具身智能发展的挑战与远程操作平台的关键价值
人形机器人需要在不确定环境中与各种物体进行精确交互,包括抓取、推拉、操作工具等,这需要精细的力控制和触觉反馈。
在开放环境中,机器人需要理解复杂场景、识别物体、理解人类指令并做出适当反应,这需要强大的AI和深度学习能力。
人形机器人需要高效的能量管理系统,既要提供足够的动力和续航能力,又要避免过热和能量浪费。
人形结构的动态平衡控制极其复杂,尤其在不平坦地形或执行高难度动作时,需要复杂的传感器融合和反馈控制。
高性能的执行器、传感器和计算平台使人形机器人成本居高不下,限制了大规模商业化应用。
整合机械、电子、算法和控制系统需要跨学科协作,任何单一环节的瓶颈都会影响整体性能。

全球领先的人工智能及人形机器人公司,明星产品Walker系列,覆盖教育、物流、康养等领域。
通过商用服务机器人、教育机器人及行业解决方案销售,形成"硬件+软件+服务"生态闭环。

Optimus人形机器人计划2025年量产,目标成本低于2万美元,应用于工业场景(工厂自动化与仓储管理)。
硬件销售整合至特斯拉生态系统,未来结合自动驾驶技术提供工业服务。

2025年推出人形机器人H1,面向工业与消费场景,计划推进量产,曾在春晚展示灵活动作。
以高性能机器人硬件销售切入工业搬运、娱乐表演市场,未来希望拓展家庭服务。

以Atlas(高动态运动能力)和Spot机器人闻名,技术领先,重点布局物流和工业检测场景。
通过技术授权、Spot机器狗租赁及仓储自动化等定制化解决方案盈利。

Figure 02机器人进入商业化验证阶段,应用于仓储和零售场景,强调人机协作能力。
B端企业合作提供物流搬运、零售服务解决方案,未来可能拓展家庭助理领域。
接触动力学和摩擦力的精确建模(动静摩擦的转换、表面粘性、接触时的微观形变)
不同材质表面间相互作用的复杂性
柔性材料和变形的准确模拟
传感器噪声和延迟的真实建模
执行器响应时间、疲劳和磨损特性


通过学习视频大模型是否能理解物理规律?
"看起来正确"的表面现象对训练机器人是否足够?
复杂物理互动监督精度(和面、叠衣服、系/解绳、烹饪)
如何模拟机器人的力学反馈信号
Sim-to-Real Gap
语言大模型的发展路径为具身智能提供了重要启示:
具身智能发展可能需要类似路径:先通过大量仿真数据、空间智能建立基础模型,再通过大量真实机器人与物理世界交互数据优化。
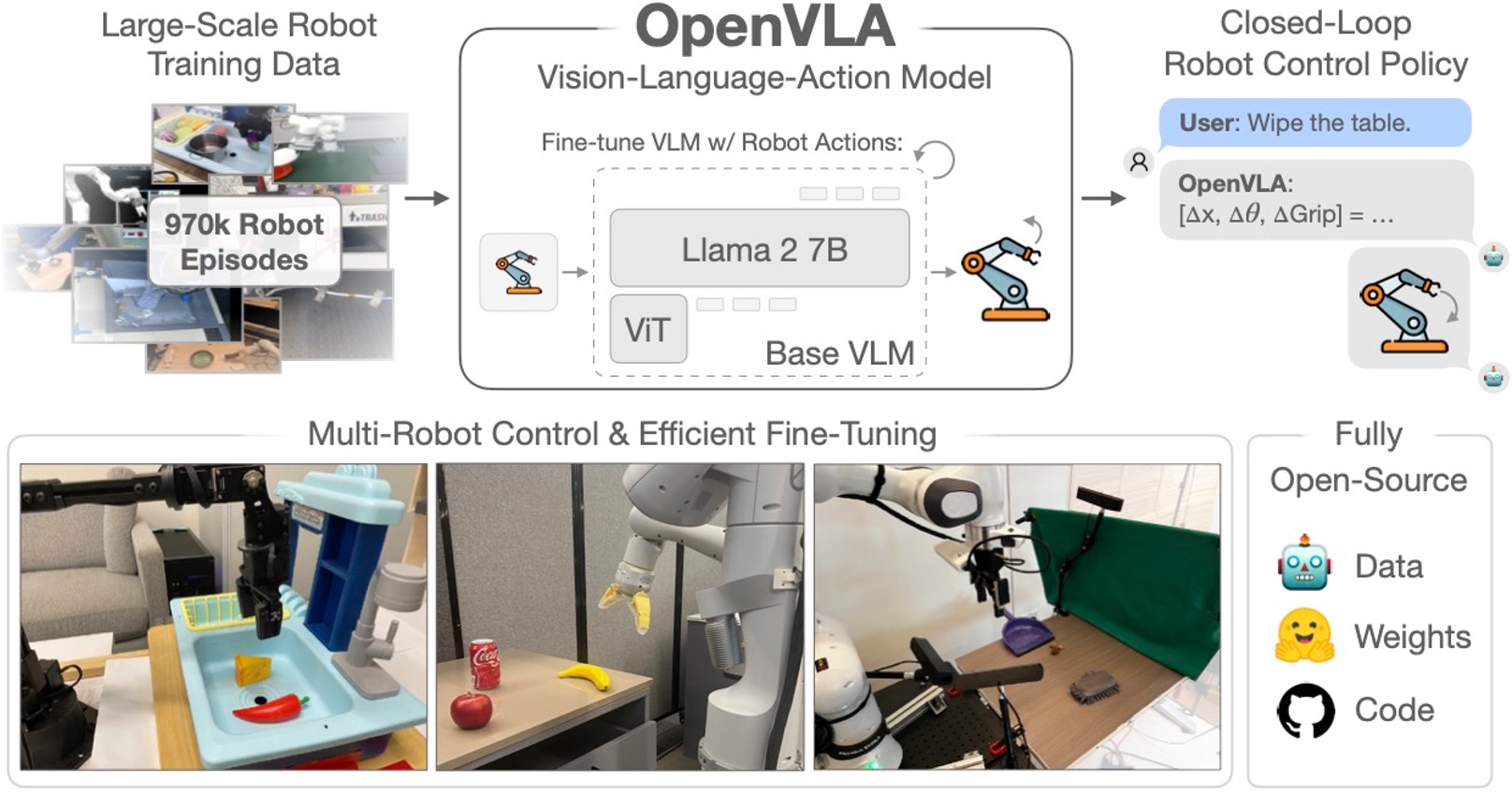
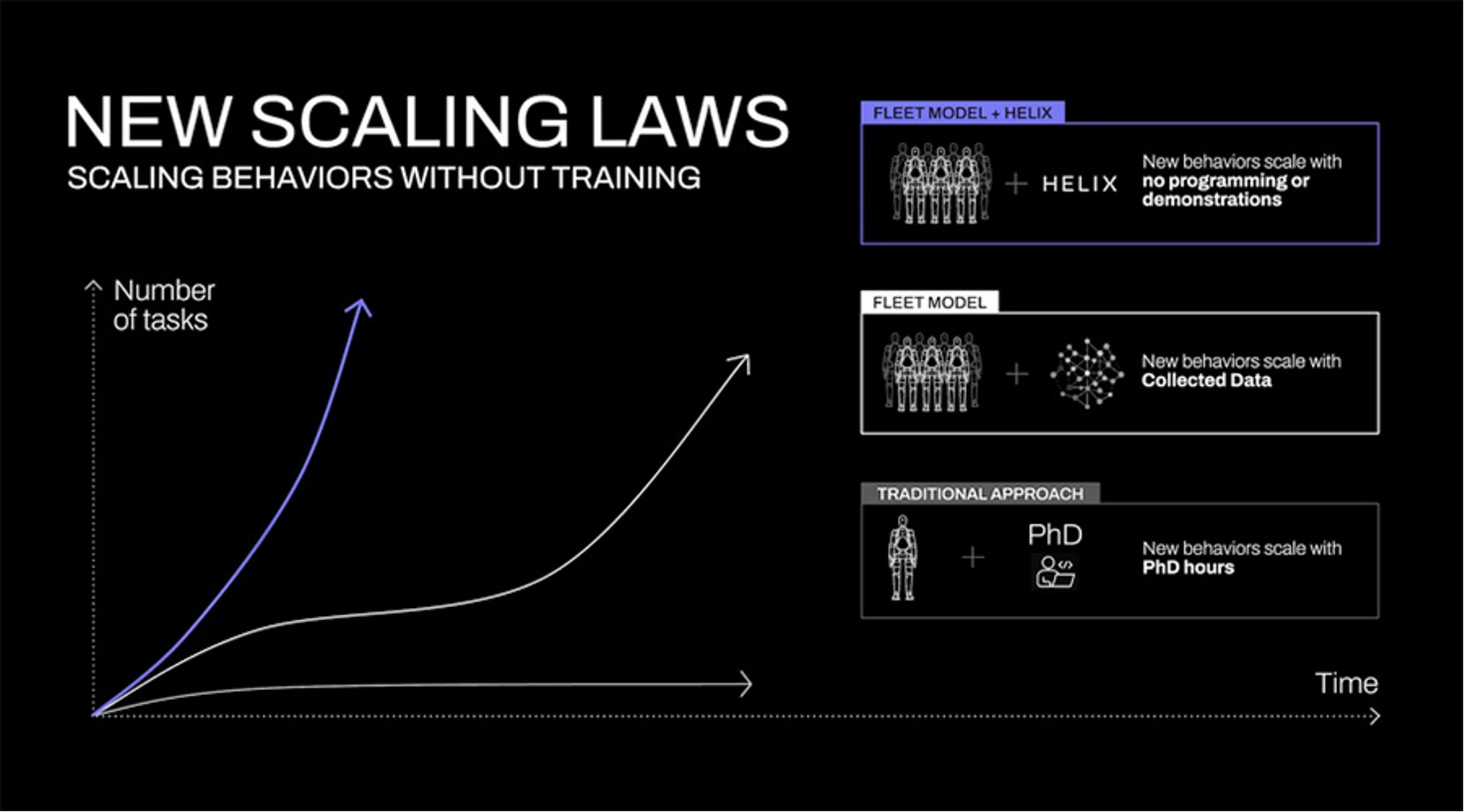
与语言大模型类似,具身智能也可能遵循特定的扩展规律:
目前具身智能领域的数据集规模与语言大模型相比存在巨大差距:
参考:主要数据集包括RoboNet(15K轨迹)、Berkeley RPWIO(6万交互)、BAIR(4万抓取)、Something-Something V2(22万视频)、Epic-Kitchens(100+小时)、DeepMind(数十万轨迹)等。
* 详细数据参见《具身智能数据集研究报告》,2025
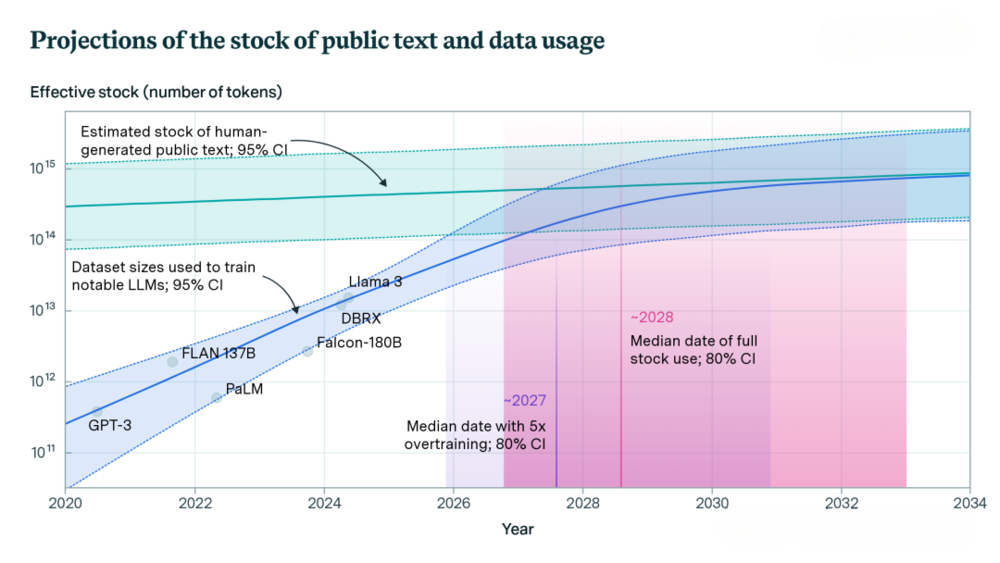
与语言大模型相比,具身智能面临的最大挑战之一是数据规模差距:
这种差距说明我们需要构建更大规模、更高质量的具身智能数据集,而远程操作平台正是实现这一目标的关键路径。
远程操作平台是收集真实物理环境下人类专家控制数据的最有效途径,这些数据对于具身智能的发展至关重要:

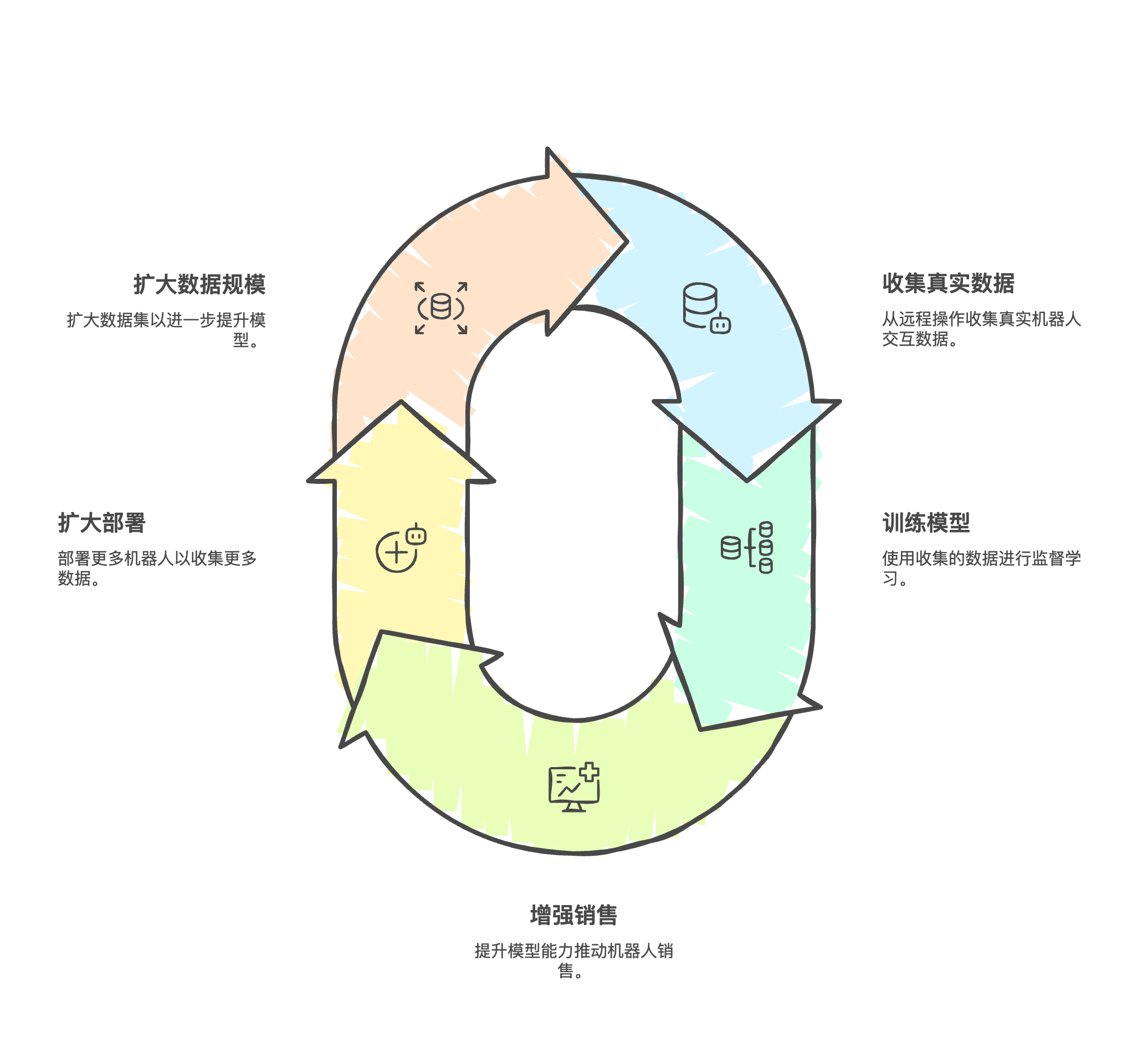
远程操作平台能够创造正向的数据增长循环,推动具身智能快速发展:
这种正向循环可以加速具身智能从实验室走向真实应用,类似于自动驾驶领域Tesla通过车队数据收集所实现的领先优势。
远程操作平台在不同自动化水平之间架起了关键桥梁:
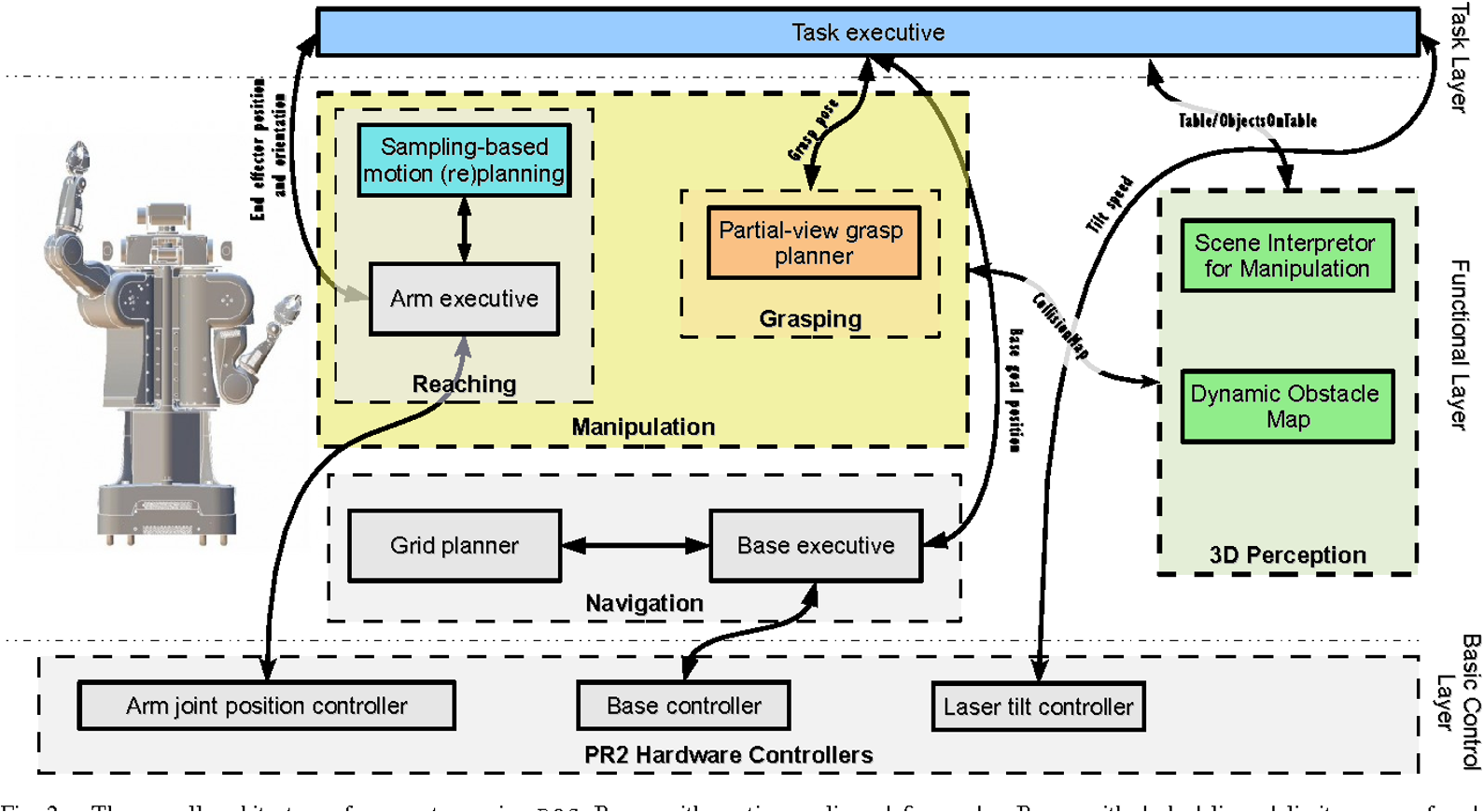
Tele-operation平台是这一进阶过程的关键enabler,通过"人在环路"(Human-in-the-Loop)方式,逐步提升自动化水平,最终实现更高效、更安全的机器人应用。
